Big-Data ist als „Buzz-Wort“ in aller Munde. Laut Wikipedia wird damit in der Informatik der Problembereich von Daten und ihrer Verarbeitungstechnologien bezeichnet, die entweder sehr groß, sehr komplex, sehr schnelllebig oder sehr schwach strukturiert sind und sich deswegen manuell oder mit herkömmlichen Methoden der Datenverarbeitung nicht verarbeiten lassen.
Bei Cyface arbeiten wir mit verschränkten Datenströmen, die durch GPS Sensoren, Accelerometer, Gyroskop und Magnetometer erzeugt werden. Jeder dieser Datenströme umfasst jeweils mehrere Datenpunkte, die je nach Sensor im Millisekundentakt ankommen. Eine komplette Erfassung Deutschlands würde nach derzeitigem Stand knapp 7 Terrabyte an Daten erzeugen. Wir können bei Cyface also durchaus von großen, komplexen und schnelllebigen Daten sprechen. Trotzdem arbeiten wir derzeit mit einer klassischen Serveranwendung und einer relationalen Datenbank. Diese Lösung stößt nach 6 Monaten der Datenerfassung nun langsam an ihre Grenzen, was bedeutet, dass wir über die nächste Zeit auf Big-Data-Technologien umsteigen werden. Um das „Buzz-Wort“ zu entzaubern meinen wir mit Big-Data an dieser Stelle immer das die horizontale Skalierbarkeit des Systems sichergestellt werden soll, denn dies ist das eigentlich zu lösende Problem. Dieser Beitrag soll einen kurzen Einblick über unsere Erkenntnisse bezüglich solcher Ansätze geben und vielleicht auch den einen oder anderen Tipp für diejenigen enthalten, die vor einem ähnlichen Schritt stehen.
Datenumfang
Zunächst soll der aktuelle Datenbestand nach 6 Monaten geschlossener Betaphase, kurz vorgestellt werden. An sich wäre der Datenbestand noch mit herkömmlicher vertikaler Skalierung zu verarbeiten. Da wir allerdings an die Grenzen unseres zugegebenermaßen recht bescheidenen Servers stoßen und das Wachstum der Datenmenge auf eine notwendige horizontale Skalierung in der näheren Zukunft hindeutet, soll diese begonnen werden, bevor es extrem dringend wird. Big-Data ist somit immer aus der perspektive der zur Verfügung stehenden Ressourcen zu betrachten. Wenn ich nur einen Schrank voller RaspberryPi-Computer habe können schon sehr kleine Datensätze unter die Big-Data Problematik fallen.
Der Cyface Datensatz umfasst derzeit ungefähr 70 GB an Daten. Diese setzen sich aus 13.000 gefahrenen Kilometer mit 56 aktiven Geräten in der geschlossenen Betaphase zusammen. Die erste Aufzeichnung ist vom 3. Juni 2016. Dabei hat sich der aktivste Nutzer mit 2.400 km beteiligt, während das inaktivste Gerät Daten für 1,3 km geliefert hat. Etwa 4.000 km wurden mit dem Fahrrad und etwas über 9.000 mit dem Auto gefahren. Im Gesamten Zeitraum ist der Datensatz ungefähr linear gemäß folgender Abbildung gewachsen.
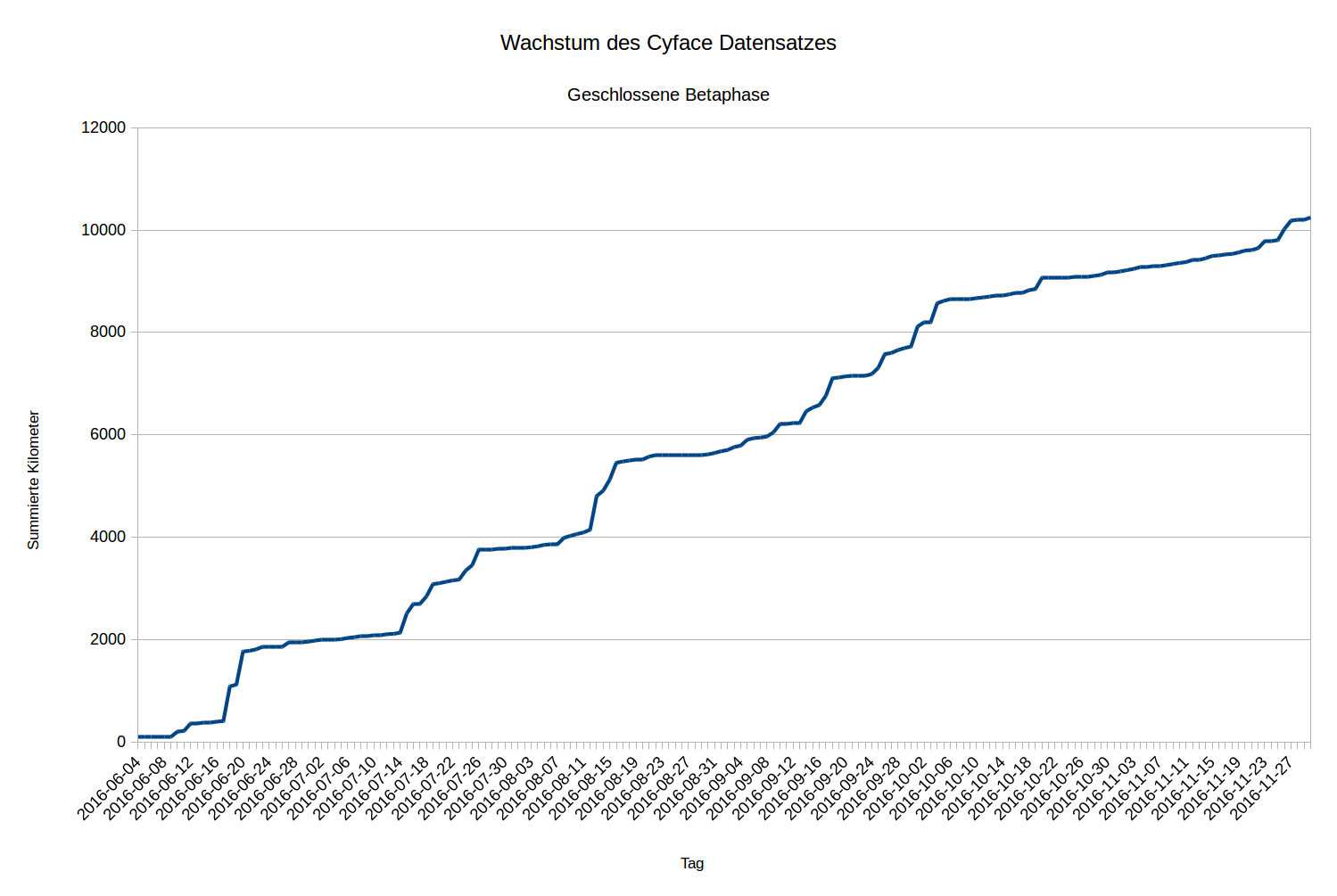
Wachstum des Cyface Datensatzes
Ein paar größere Sprünge bezeichnen größere Fahrten. Die Grafik erreicht nicht ganz die 13.000 Kilometer, weil einige Zeitstempel unserer Messbox, basierend auf RaspberryPi Technologie, zwar in der Reihenfolge aber nicht in der tatsächlichen Zeit korrekt sind. Das liegt insbesondere daran, dass der RaspberryPi keinen internen Zeitgeber hat.
Verarbeitung von Big-Data
Wenn man beginnt sich mit dem Thema horizontale Skalierung zu beschäftigen, stößt man umgehend auf einen undurchdringlichen Dschungel an Frameworks, Technologien und Konzepten die es zu sortieren gilt bevor man auswählt mit welcher man beginnt. Im Folgenden eine nicht notwendigerweise vollständige Liste relevanter Begriffe mit jeweils einer kurzen Erklärung
Frameworks zur Datenverarbeitung
Hadoop Dies ist sicherlich der erste Begriff der jedem in den Sinn kommt, der schon mal etwas von Big-Data-Processing gehört hat. Hadoop basiert auf dem ursprünglichen Map/Reduce Konzept und bietet einen ganzen Stapel von Technologien zur Realisierung eines horizontal skalierenden Systems. HDFS ist das Hadoop Dateisystem (Hadoop File System) zur Ablage von Daten. YARN (Yet Another Resource Negotiator) wird als zentraler Verwaltungsknoten für die einzelnen Arbeiter verwendete. Schließlich gibt es noch den Kern (Core) der die anderen Komponenten zusammen führt und eine Programmier-API für Java zur Verfügung stellt. Viele weitere Projekte bauen auf Hadoop auf.
Apache Apex Apache Apex ist ein Framework zur Verarbeitung von Datenströmen, welches auf HDFS und YARN als Ressourcenverwalter beruht. Wie die meisten Big-Data-Frameworks basiert es auf dem funktionalen Programmiermodell. Bemerkenswert ist allerdings, dass Apex im Gegensatz zur üblichen funktionalen Programmierung einen Zustand erlaubt.
Apache Spark Spark ist ein Framework, welches die horizontal skalierte Verarbeitung von Daten in einem Cluster erlaubt. Es kann verschiedene Speichertechnologien wie HDFS nutzen und erweitert die klassischen funktionalen Verarbeitungsoperatoren „Map“ und „Reduce“ um weitere, was die Verwendung von Spark gegenüber Hadoop für gewisse Aufgaben, die sich durch „Map“ und „Reduce“ allein nur schwer abbilden lassen, deutlich vereinfacht. Für Spark gibt es verschiedene Erweiterungen und darauf aufbauende Technologien für Spezialaufgaben.
Spark Timeseries Eine für Cyface besonders interessante Erweiterung von Spark ist Spark Timeseries. Es erlaubt die verteilte Verarbeitung von Zeitreihen basierend auf Apache Spark. Zeitreihen können zum Beispiel von GPS – und Accelerometersensoren generierte Werte mit Zeitstempel sein.
Apache Storm System zur Verarbeitung von Datenströmen in Echtzeit.
Apache Beam Beam ist ein System zur Verarbeitung von Batch und Streaming Aufgaben. Es stellt dabei keine Konkurrenz zu Frameworks wie Apex oder Spark dar, sondern baut auf diesen auf. Derzeit befindet es sich noch im „Incubating“ Status.
Datenhaltung
Hive Dies stellt eine Datenbank dar, die sich per SQL anfragen lässt tatsächlich aber verteilt vorliegt. Als ursprünglicher Teil von Hadoop, kann Hive das HDFS für die Datenablage nutzen.
Cassandra Eine weitere verteilte Datenbank wird durch Cassandra bereit gestellt. Im Gegensatz zu Hive verfolgt Cassandra kein relationales Datenbankmodell und ist darum schemafrei.
Mongo DB Dies ist eine der am weitesten verbreiteten Dokumentendatenbanken. Wie Cassandra ist Mongo DB schemafrei. Eine Dokumentendatenbank folgt einem ähnlichen Format wie zum Beispiel JSON.
HBase Eine Datenbank basierend auf Hadoop und HDFS wird durch HBase bereit gestellt. Das Konzept on HBase folgt der BigTables Technologie von Google.
Verteilte Datenkommunikation
Redis Ein verteilter Cache für Daten im Speicher. Das ist möglicherweise in Hochverfügbarkeitsszenarien relevant. Da Cyface grundsätzlich nur im Bereich von Tagen aktuell sein muss ist diese Technologie zunächst nicht so wichtig.
Kafka Ein verteilter Nachrichtenbus der häufig für das Verarbeiten komplexer Ereignisse (CEP – Complex Event Processing) und die Implementierung von Micro-Service-Architekturen verwendet wird.
RabbitMQ Dies ist eine Implementierung von AMQP, also ähnlich wie Kafka ein Message Queue über welchen Micro-Service-Architekturen kommunizieren können.
Horizontal skalierende Platformen
Mesos Diese Technologie bezeichnet sich selbst als verteilten Systemkern. Im Grunde ist es eine verteilte Virtualisierungsschicht die es Frameworks erlaubt Jobs dynamisch über Clusterknoten zu verteilen.
Kubernets Ist eine verteilte Platform für Anwendungscontainer, um Anwendungen isoliert verteilt laufen zu lassen.
OpenStack Die wohl am weitesten verbreitete Umgebung zum Betrieb einer eignen Cloud. OpenStack bietet dynamsiche Verwaltung von Speicher und CPUs und die Virtualisierung des Netzwerks. Bis auf den Fakt das Java hier als Buh-Mann dargestellt wird gibt es hier eine sehr schöne Erklärung zu dieser Technologie.
Zusammenfassung
Obwohl wir uns sicherlich noch mit vielen Technologien beschäftigen müssen und werden, ist der erste Schritt die Integration eines Apache Spark Clusters in die Architektur von Cyface. Dies soll sicherstellen, dass wir insbesondere die verfügbaren Ressourcen vollständig nutzen können. Aufbauend darauf werden wir die Nutzung einer Streaming-Technologie evaluieren, wobei Echtzeit im Moment nicht besonders wichtig ist. Während unser Wissen zu diesen Technologien und den Zusammenhängen wächst werden wir diesen Beitrag nutzen, um eine Gesamtbild des Problembereichs zu skizzieren.